309784: CF1735C. Phase Shift
Memory Limit:256 MB
Time Limit:3 S
Judge Style:Text Compare
Creator:
Submit:0
Solved:0
Description
Phase Shift
题意翻译
## 题目描述 有一个应该被加密的字符串 $s$ 。为此,所有$26$个小写英文字母按一定顺序排列在一个圆圈中,之后,$s$中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了$t$ 这个字符串。 给你一个字符串 $t$。请确定在字典序上最小的字符串 $s$,使得它可能是是给定字符串 $t$ 的原型。 ## 输入 输入的第一行包含一个整数 $t(1≤t≤3⋅10^4)$表示测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 $n(1≤n≤10^5)$ ,表示字符串 $t$ 的长度。 下一行输入长度为 $n$ 的字符串 $t$ ,只包含小写英文字母。 保证所有测试用例的 $n$ 之和不超过 $2⋅10^5$。 ## 输出格式 对于每个测试用例,输出一行,表示字典序上最小的,可能是 $t$ 的原型的字符串 $s$ 。 ## 样例解释 在第一个测试案例中,我们不可能有 `"a"` 这个字符串,因为字母 $a$ 会转给它自己。从词汇学上看,第二个字符串 `"b"` 适合作为答案。 在第二个测试案例中,字符串 `"aa"` 不适合,因为a会转移到它自己。`"ab"` 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 `"ac"`是合适的。 下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。题目描述
There was a string $ s $ which was supposed to be encrypted. For this reason, all $ 26 $ lowercase English letters were arranged in a circle in some order, afterwards, each letter in $ s $ was replaced with the one that follows in clockwise order, in that way the string $ t $ was obtained. You are given a string $ t $ . Determine the lexicographically smallest string $ s $ that could be a prototype of the given string $ t $ . A string $ a $ is lexicographically smaller than a string $ b $ of the same length if and only if: - in the first position where $ a $ and $ b $ differ, the string $ a $ has a letter, that appears earlier in the alphabet than the corresponding letter in $ b $ .输入输出格式
输入格式
The first line of the input contains a single integer $ t $ ( $ 1 \le t \le 3 \cdot 10^4 $ ) — the number of test cases. The description of test cases follows. The first line of each test case contains one integer $ n $ ( $ 1 \le n \le 10^5 $ ) — the length of the string $ t $ . The next line contains the string $ t $ of the length $ n $ , containing lowercase English letters. It is guaranteed that the sum of $ n $ over all test cases doesn't exceed $ 2 \cdot 10^5 $ .
输出格式
For each test case, output a single line containing the lexicographically smallest string $ s $ which could be a prototype of $ t $ .
输入输出样例
输入样例 #1
5
1
a
2
ba
10
codeforces
26
abcdefghijklmnopqrstuvwxyz
26
abcdefghijklmnopqrstuvwxzy输出样例 #1
b
ac
abcdebfadg
bcdefghijklmnopqrstuvwxyza
bcdefghijklmnopqrstuvwxyaz说明
In the first test case, we couldn't have the string "a", since the letter a would transit to itself. Lexicographically the second string "b" is suitable as an answer. In the second test case, the string "aa" is not suitable, since a would transit to itself. "ab" is not suitable, since the circle would be closed with $ 2 $ letters, but it must contain all $ 26 $ . The next string "ac" is suitable. Below you can see the schemes for the first three test cases. The non-involved letters are skipped, they can be arbitrary placed in the gaps. 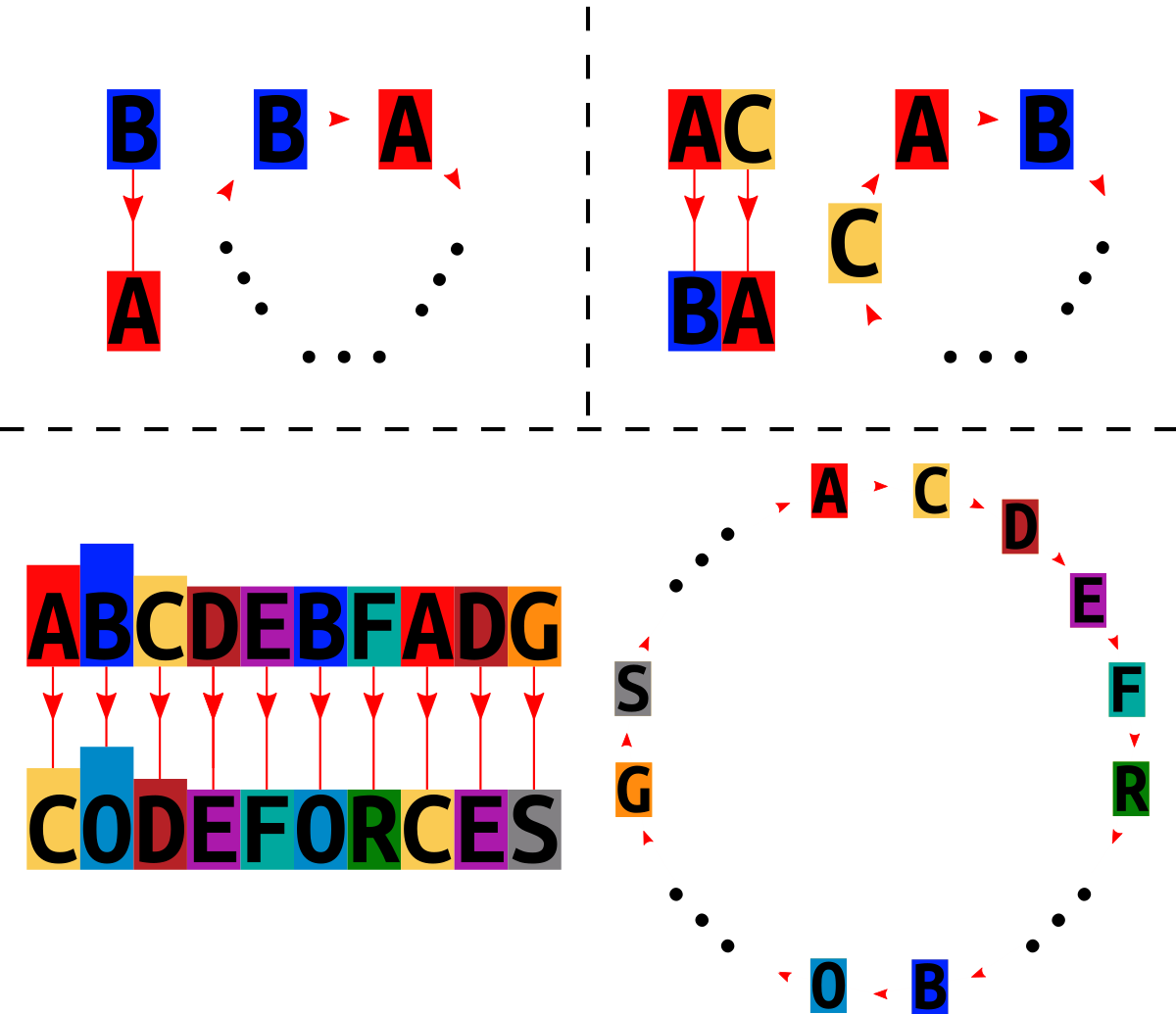Input
题意翻译
## 题目描述 有一个应该被加密的字符串 $s$ 。为此,所有$26$个小写英文字母按一定顺序排列在一个圆圈中,之后,$s$中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了$t$ 这个字符串。 给你一个字符串 $t$。请确定在字典序上最小的字符串 $s$,使得它可能是是给定字符串 $t$ 的原型。 ## 输入 输入的第一行包含一个整数 $t(1≤t≤3⋅10^4)$表示测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 $n(1≤n≤10^5)$ ,表示字符串 $t$ 的长度。 下一行输入长度为 $n$ 的字符串 $t$ ,只包含小写英文字母。 保证所有测试用例的 $n$ 之和不超过 $2⋅10^5$。 ## 输出格式 对于每个测试用例,输出一行,表示字典序上最小的,可能是 $t$ 的原型的字符串 $s$ 。 ## 样例解释 在第一个测试案例中,我们不可能有 `"a"` 这个字符串,因为字母 $a$ 会转给它自己。从词汇学上看,第二个字符串 `"b"` 适合作为答案。 在第二个测试案例中,字符串 `"aa"` 不适合,因为a会转移到它自己。`"ab"` 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 `"ac"`是合适的。 下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。Output
**题意翻译**
题目描述:有一个应该被加密的字符串 \( s \)。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。
给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。
输入:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) 表示测试案例的数量。每个测试用例的描述如下。
每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \),表示字符串 \( t \) 的长度。
下一行输入长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。
保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。
输出格式:对于每个测试用例,输出一行,表示字典序上最小的,可能是 \( t \) 的原型的字符串 \( s \)。
题目描述:有一个字符串 \( s \),它被加密。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。
给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。
输入输出格式
输入格式:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) — 测试案例的数量。每个测试用例的描述如下。
每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \) — 字符串 \( t \) 的长度。
下一行包含长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。
保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。
输出格式:对于每个测试用例,输出一行,包含可能是 \( t \) 的原型的,字典序上最小的字符串 \( s \)。
输入输出样例
输入样例 #1:
```
5
1
a
2
ba
10
codeforces
26
abcdefghijklmnopqrstuvwxyz
26
abcdefghijklmnopqrstuvwxzy
```
输出样例 #1:
```
b
ac
abcdebfadg
bcdefghijklmnopqrstuvwxyza
bcdefghijklmnopqrstuvwxyaz
```
说明:在第一个测试案例中,我们不可能有字符串 "a",因为字母 'a' 会转给它自己。从词汇学上看,第二个字符串 "b" 适合作为答案。
在第二个测试案例中,字符串 "aa" 不适合,因为 'a' 会转移到它自己。"ab" 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 "ac" 是合适的。
下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。**题意翻译** 题目描述:有一个应该被加密的字符串 \( s \)。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。 给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。 输入:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) 表示测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \),表示字符串 \( t \) 的长度。 下一行输入长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。 保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。 输出格式:对于每个测试用例,输出一行,表示字典序上最小的,可能是 \( t \) 的原型的字符串 \( s \)。 题目描述:有一个字符串 \( s \),它被加密。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。 给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。 输入输出格式 输入格式:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) — 测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \) — 字符串 \( t \) 的长度。 下一行包含长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。 保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。 输出格式:对于每个测试用例,输出一行,包含可能是 \( t \) 的原型的,字典序上最小的字符串 \( s \)。 输入输出样例 输入样例 #1: ``` 5 1 a 2 ba 10 codeforces 26 abcdefghijklmnopqrstuvwxyz 26 abcdefghijklmnopqrstuvwxzy ``` 输出样例 #1: ``` b ac abcdebfadg bcdefghijklmnopqrstuvwxyza bcdefghijklmnopqrstuvwxyaz ``` 说明:在第一个测试案例中,我们不可能有字符串 "a",因为字母 'a' 会转给它自己。从词汇学上看,第二个字符串 "b" 适合作为答案。 在第二个测试案例中,字符串 "aa" 不适合,因为 'a' 会转移到它自己。"ab" 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 "ac" 是合适的。 下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。
题目描述:有一个应该被加密的字符串 \( s \)。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。
给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。
输入:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) 表示测试案例的数量。每个测试用例的描述如下。
每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \),表示字符串 \( t \) 的长度。
下一行输入长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。
保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。
输出格式:对于每个测试用例,输出一行,表示字典序上最小的,可能是 \( t \) 的原型的字符串 \( s \)。
题目描述:有一个字符串 \( s \),它被加密。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。
给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。
输入输出格式
输入格式:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) — 测试案例的数量。每个测试用例的描述如下。
每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \) — 字符串 \( t \) 的长度。
下一行包含长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。
保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。
输出格式:对于每个测试用例,输出一行,包含可能是 \( t \) 的原型的,字典序上最小的字符串 \( s \)。
输入输出样例
输入样例 #1:
```
5
1
a
2
ba
10
codeforces
26
abcdefghijklmnopqrstuvwxyz
26
abcdefghijklmnopqrstuvwxzy
```
输出样例 #1:
```
b
ac
abcdebfadg
bcdefghijklmnopqrstuvwxyza
bcdefghijklmnopqrstuvwxyaz
```
说明:在第一个测试案例中,我们不可能有字符串 "a",因为字母 'a' 会转给它自己。从词汇学上看,第二个字符串 "b" 适合作为答案。
在第二个测试案例中,字符串 "aa" 不适合,因为 'a' 会转移到它自己。"ab" 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 "ac" 是合适的。
下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。**题意翻译** 题目描述:有一个应该被加密的字符串 \( s \)。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。 给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。 输入:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) 表示测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \),表示字符串 \( t \) 的长度。 下一行输入长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。 保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。 输出格式:对于每个测试用例,输出一行,表示字典序上最小的,可能是 \( t \) 的原型的字符串 \( s \)。 题目描述:有一个字符串 \( s \),它被加密。为此,所有26个小写英文字母按一定顺序排列在一个圆圈中,之后,\( s \) 中的每个字母按顺时针顺序被替换成后面的字母,这样就得到了 \( t \) 这个字符串。 给你一个字符串 \( t \)。请确定在字典序上最小的字符串 \( s \),使得它可能是给定字符串 \( t \) 的原型。 输入输出格式 输入格式:输入的第一行包含一个整数 \( t (1 \le t \le 3 \cdot 10^4) \) — 测试案例的数量。每个测试用例的描述如下。 每个测试用例的第一行包含一个整数 \( n (1 \le n \le 10^5) \) — 字符串 \( t \) 的长度。 下一行包含长度为 \( n \) 的字符串 \( t \),只包含小写英文字母。 保证所有测试用例的 \( n \) 之和不超过 \( 2 \cdot 10^5 \)。 输出格式:对于每个测试用例,输出一行,包含可能是 \( t \) 的原型的,字典序上最小的字符串 \( s \)。 输入输出样例 输入样例 #1: ``` 5 1 a 2 ba 10 codeforces 26 abcdefghijklmnopqrstuvwxyz 26 abcdefghijklmnopqrstuvwxzy ``` 输出样例 #1: ``` b ac abcdebfadg bcdefghijklmnopqrstuvwxyza bcdefghijklmnopqrstuvwxyaz ``` 说明:在第一个测试案例中,我们不可能有字符串 "a",因为字母 'a' 会转给它自己。从词汇学上看,第二个字符串 "b" 适合作为答案。 在第二个测试案例中,字符串 "aa" 不适合,因为 'a' 会转移到它自己。"ab" 不合适,因为圆圈会被 2 个字母封闭,但它必须包含全部 26 个字母。下一个字符串 "ac" 是合适的。 下面你可以看到前三个测试案例的方案。不涉及的字母被跳过,它们可以被任意放在空隙中。